Modern Java Ch06. Stream으로 데이터 수집
통화별로 트랜잭션을 그룹화한 코드 (명령형 버전)
Map<Currenct, List<Transaction>> transactionByCurrencies = new HashMap<>();
for(Transaction transaction : transactions) {
Currency currency = transaction.getCurrency();
List<Transaction> transactionForCurrency = transactionByCurrencies.get(currency);
if(transactionForCurrency == null) {
transactionForCurrencies = new ArrayList<>();
transactionForCurrencies.put(currency, transactionsForCurrency);
}
transactionForCurrency.add(transaction);
}
return transactionForCurrency;어렵게 구현은 했는데 이해하기 어려운 코드가 되어버렸다.
'통화별로 트랜잭션 리스트를 그룹화하시오'라고 간단히 표현할 수 있지만 코드가 무엇을 실행하는지 한눈에 파악하기 어렵다.
Map<Currency, List<Transaction>> transactionByCurrencies =
transactions.stream().collect(groupingBy(transaction::getCurrency));Stream에 toList를 사용하는 대신 더 범용적인 컬렉터 파라미터를 collect 메서드에 전달함으로써
원하는 연산을 간결하게 구현할 수 있음을 지금부터 배우게 될 것이다.
컬렉터란 무엇인가?
- 함수형 프로그래밍에서는 '무엇'을 원하는지 직접 명시할 수 있어서 어떤 방법으로 이를 얻을지는 신경 쓸 필요가 없다.
- Collector 인터페이스 구현은 스트림의 요소를 어떤 식으로 도출할지 지정한다.
- 명령형 코드에서는 문제를 해결하는 과정에서 다중 루프와 조건문을 추가하며 가독성과 유지보수성이 크게 떨어진다.
- 고급 리듀싱 기능을 수행하는 컬렉터
- 훌륭하게 설계된 함수형 API의 또 다른 장점으로 높은 수준의 조합성과 재사용성을 꼽을 수 있다.
- collect로 결과를 수집하는 과정을 간단하면서도 유연한 방식으로 정의할 수 있다는 점이 컬렉터의 최대 강점이다.
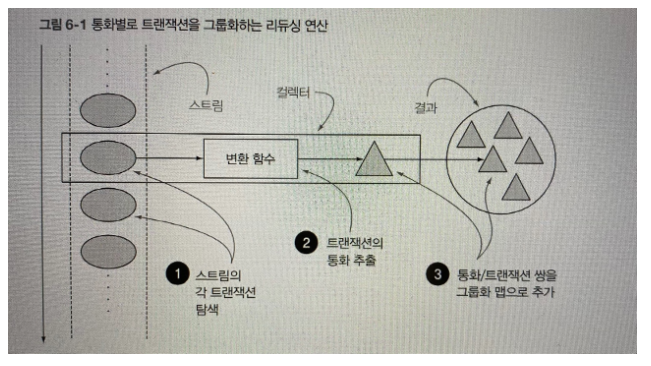
내부적으로 리듀싱 연산이 일어나는 모습
- 미리 정의된 컬렉터
- Collectors에서 제공하는 메서드의 기능은 크게 세 가지로 구분할 수 있다.
- 스트림 요소를 하나의 값으로 리듀스하고 요약
- 요소 그룹화
- 요소 분할
리듀싱과 요약
이전예제에서 배웠듯이 컬렉터(Stream.collect 메서드의 인수)로 스트림의 항목을 컬렉션으로 재구성할 수 있다.
long howManyDishes = menu.stream().collect(Collectors.counting());
long howManyDishes = menu.stream().count();좀 더 일반적으로 말해 컬렉터로 스트림의 모든 항목을 하나의 결과로 합칠수 있다.
- 스트림값에서 최댓갑과 최솟값 검색
메뉴에서 칼로리가 가장 높은 요리를 찾는다고 가정하자
Collectorsr.maxBy, Collectors.minBy 두 개의 메서드를 이용해서 스트림의 최댓값과 최솟값을 계산할 수 있다.
두 메서드는 스트림의 요소를 비교하는 데 사용할 Comparator를 인수로 받는다.
Comparator<Dish> dishCaloriesComparator = Comparator.comaringInt(Dish::getCalories);
OPtional<Dish> mostCalorieDish = menu.stream().collect(max(dishCaloriesComparator));
스트림에 있는 객체의 숫자 필드의 합계나 평균 등을 반환하는 연산에도 리듀싱 기능이 자주 사용된다. 이러한 연산을 요약(summarization)연산이라 부른다.
- 요약 연산 Collectors 클래스는 Collectors.summingInt라는 특별한 요약 팩토리 메서드를 제공한다.
int totalCalories = menu.stream().collect(summingInt(Dish::getCalroeis));summingInt는 객체를 int로 매핑하여 누적 합계를 계산해준다.
마찬가지로 int뿐 아니라 long이나 double에 대응하는 summaringLong, summarizingDouble 메서드와 관련된 LongSummaryStatistics, DoubleSummaryStatistics 클래스도 있다.

- 문자열 연결 컬렉터에 joining 팩토리 메서드를 이용하면 스트림의 각 객체에 toString 메서드를 호출해서 추출한 모든 문자열을 하나의 문자열로 연결해서 반환한다.
String shortMenu = menu.stream().map(Dish::getName).collect(joinging());
//abcde
String shortMenu = menu.stream().map(Dish::getName).collect(joinging(", ")); // ,로 구분해줄수 있다.
//a,b,c,d,ejoining 메서드는 내부적으로 내부적으로 StringBuilder를 이용해서 문자열을 하나로 만든다.
- 범용 리듀싱 요약 연산 지금까지 살펴본 모든 컬렉터는 reducing 팩토리 메서드로도 정의할 수 있다.
그럼에도 이전 예제에서 범용 팩토리 메서드 대신 특화된 컬렉터를 사용한 이유는 프로그래밍적 편의성 때문이다.
(하지만 프로그래머의 편의성 뿐만 아니라 가독성도 중요하다는 사실을 기억하자)
// Collectors.reducing 범용 팩토리 메서드 사용 \
int totalCalories = menu.stream().collect(reducing(0, Dish::getCalories, (i, j) -> (i + j));
int totalCalories = menu.stream().collect(reducing(0, Dish::getCalories, Integer::sum); // 특화된 컬렉터 사용
int totalCalories = menu.stream().collect(summingInt(Dish::getCalories));reducing은 세 개의 인수를 받는다.
첫 번째 인수는 리듀싱 연산의 시작값이거나 스트림에 인수가 없을 때는 반환값이다.
두 번째 인수는 요리를 칼로리 정수 변환할 때 사용한 변환 함수다
세 번째 인수는 같은 종류의 두 항목을 하나의 값으로 더하는 BinaryOperator다.
- collect vs reduce collect 메서드는 결과를 누적하는 컨테이너를 변경하도록 설계된 메서드
reduce 메서드는 두 값을 하나로 도출하는 불변형 연산하는 메서드
컬렉션 프레임워크 유연성: 같은 연산도 다양한 방식으로 수행할 수 있다!
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);
// 1. reduce
// 병렬 처리 시 각자 다른 쓰레드에서 실행한 결과를 마지막에 합치는 단계
// 병렬 스트림에서만 동작
List<Integer> numbers = stream.reduce(
new ArrayList<Integer>(),
(List<Integer> l, Integer e) -> {
l.add(e);
return l;
},
(List<Integer> l1, List<Integer> l2) -> {
l1.addAll(l2);
return l1;
}
);
// 2. collect
List<Integer> numbers = stream.collect(Collectors.toList());collect : 도출하려는 결과를 누적하는 컨테이너를 바꾸도록 설계가 되어있는 메서드
reduce : 두 값을 하나로 도출하는 불변형 연산 하는 메서드
따라서 위의 reduce는 누적자로 사용된 리스트를 변환시키므로 잘못 활용한 예이다.
여러 스레드가 동시에 데이터 구조체(여기서는 list)를 수정하게 되면 리스트 자체가 망가져 병렬 연산 수행 불가
위의 문제를 해결하기 위해 매번 새로운 리스트를 할당해야함 그렇게 된다면 성능 저하
결론 : 가변 컨테이너 관련 작업이면서 병렬성을 확보하려면 collect 메서드로 리듀싱 연산을 구현하는 것이 바람직하다.
자신의 상황에 맞게 골라쓰자
하나의 연산을 다양한 방법으로 해결할 수 있다. 가장 가독성이 좋고 간결한 방법을 사용하자.
아래와 같이 메뉴의 칼로리들의 합을 구하는 스트림 연산을 사용할 수 있다.
int totalCalories = menu.stream().collect(summingInt(Dish::getCalories));
int totalCalories = menu.stream().map(Dish::getCalories).reduce(Integer::sum).get();
int totalCalories = menu.stream().mapToInt(Dish::getCalories).sum();
// 마지막 방법이 언방식도 피하고 성능상 가장 좋음. 또한 가독성이 좋고 간결하므로 세번째 방법 추천- 그룹화 데이터 집합을 하나 이상의 특성으로 분류해서 그룹화하는 연산도 데이터베이스에서 많이 수행되는 작업이다.
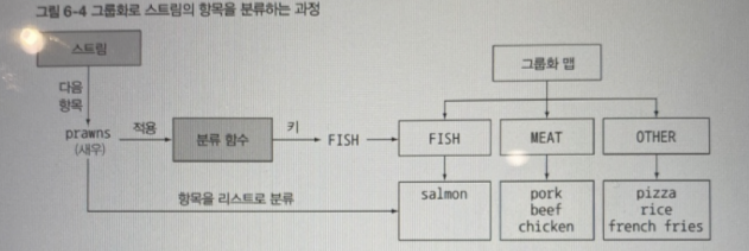
그룹화로 스트림의 항목을 분류하는 과정
단순히 객체의 필드로 분류하는 것이 아닌 복잡한 분류 기준이 필요한 경우에는
메서드참조를 사용할 수 없기 때문에 다음과 같이 람다 표현식으로 필요한 로직을 구현할 수도 있다.
public enum CaloricLevel { DIET, NORMAL, FAT }
Map<CaloricLevel, List<Dish>> dishesByCaloricLevel = menu.stream().collect(
groupingBy(dish -> {
if (dish.getCalories() <= 400) {
return CaloricLevel.DIET;
} else if (dish.getCalories() <= 700) {
return CaloricLevel.NORMAL;
} else {
return CaloricLevel.FAT ;
}
}));위와 같이 그룹화 연산의 결과로 그룹화 함수가 반환하는 키 그리고 각 키에 대응하는 스트림의 모든 항목 리스트를 값으로 갖는 맵이 반환된다.
그룹화된 요소 조작
500칼로리가 넘는 요리만 필터링하여 그룹화하고 싶다고 가정하자.
public static final List<Dish> menu = asList(
new Dish("pork", false, 800, Dish.Type.MEAT),
new Dish("beef", false, 700, Dish.Type.MEAT),
new Dish("chicken", false, 400, Dish.Type.MEAT),
new Dish("french fries", true, 530, Dish.Type.OTHER),
new Dish("rice", true, 350, Dish.Type.OTHER),
new Dish("season fruit", true, 120, Dish.Type.OTHER),
new Dish("pizza", true, 550, Dish.Type.OTHER),
new Dish("prawns", false, 400, Dish.Type.FISH),
new Dish("salmon", false, 450, Dish.Type.FISH) );
Map<Dish.Type, List<Dish>> caloricDishesByType = menu.stream().filter(
dish -> dish.getCalories() > 500).collect(groupingBy(Dish::getType));
{OTHER=[french fries, pizza], MEAT=[pork, beef]}위와 같이 코드를 짤 수 있지만, 문제가 있다.
predicate를 만족하는 FISH종류의 요리가 없으므로 결과 맵에서 해당 키 자체가 사라지게 되는 것!
아래 코드를 이용하면 맵으로 그룹핑한다음에 필터링을 수행할 수 있다.
Map<Dish.Type, List<Dish>> caloricDishesByType = menu.stream().collect(
groupingBy(Dish::getType, filtering(dish -> dish.getCalories() > 500, toList())));
//{OTHER=[french fries, pizza], MEAT=[pork, beef], FISH=[]}그 외의 groupingBy와 함께 많이 쓰이는 Collector 들을 알아보자.
- mapping 활용하기 매핑 함수를 이용해 요소를 변환할 수 있다. 요리이름 목록으로 변환
Map<Dish.Type, List<String>> dishNamesByType =
menu.stream().collect(groupingBy(Dish::getType, mapping(Dish::getName, toList())));- flatMapping 활용하기 두 수준의 리스트를 한수준으로 평탄화 작업(flatMap)이 필요할 때 사용.
각 그룹에 수행한 flatMapping 연산 결과를 수집해서 집합(set)으로 그룹화하는 작업
public static final Map<String, List<String>> dishTags = new HashMap<>();
static {
dishTags.put("pork", asList("greasy", "salty"));
dishTags.put("beef", asList("salty", "roasted"));
dishTags.put("chicken", asList("fried", "crisp"));
dishTags.put("french fries", asList("greasy", "fried"));
dishTags.put("rice", asList("light", "natural"));
dishTags.put("season fruit", asList("fresh", "natural"));
dishTags.put("pizza", asList("tasty", "salty"));
dishTags.put("prawns", asList("tasty", "roasted"));
dishTags.put("salmon", asList("delicious", "fresh"));
}
Map<Dish.Type, Set<String>> dishNamesByType =
menu.stream().collect(groupingBy(Dish::getType,
flatMapping(dish -> dishTags.get(dish.getName()).stream(), toSet())));
{
MEAT=[salty, greasy, roasted, fried, crisp],
OTHER=[salty, greasy, natural, light, tasty, fresh, fried],
FISH=[roasted, tasty, fresh, delicious]
}- 다수준 그룹화 두 인수를 받는 팩토리 메서드 Collectors.groupingBy를 이용해서 항목을 다수준으로 그룹화할 수 있다.
바깥쪽 groupingBy 메서드에 스트림의 항목을 분류할 두 번째 기준을 정의하는
내부 groupingBy를 전달해서 두 수준으로 스트림 항목을 그룹화할 수 있음.
Map<Dish.Type, Map<CaloricLevel, List<Dish>>> dishesByTypeCaloricLevel =
menu.stream().collect(
groupingBy(Dish::getType,
groupingBy(dish -> {
if (dish.getCalories() <= 400) {
return CaloricLevel.DIET;
} else if (dish.getCalories() <= 700) {
return CaloricLevel.NORMAL;
} else {
return CaloricLevel.FAT ;
}
})));
// 결과값
{
MEAT={DIET=[chicken], NORMAL=[beef], FAT=[pork]},
FISH={DIET=[prawns], NORMAL=[salmon]},
OTHER={DIET=[rice, seasonal fruit], NORMAL=[french fries, pizza]}
}
첫 번째 수준의 키 : fish, meat, other
두 번째 수준의 키 : normal, diet, fat
최종적으로 두 수준의 맵은 첫 번째 키와 두 번째 키의 기준에 부합하는 요소 리스트(chichekn, pork ..) 를 값으로 갖는다.- 서브그룹으로 데이터 수집 앞에서 두 번째 groupingBy 컬렉터를 외부 컬렉터로 전달해서 다수준 그룹화 연산을 했다.
첫 번째 groupingBy로 넘겨주는 컬렉터의 형식은 제한이 없다. => groupingBy 컬렉터에 두 번째 인수로 counting 컬렉터를 전달해서 메뉴에서 요리의 수를 종류별로 계산할 수 있다.
Map<Dish.Type, Long> typesCount = menu.strea().collect(
groupingBy(Dish::getType, counting()));
// 결과값
{MEAT=3, FISH=2, OTHER=4}분류 함수 한 개의 인수를 갖는 groupingBy(f)는 사실 groupingBy(f, toList())의 축약형
요리의 종류별로 가장 높은 칼로리를 가진 요리를 찾아보자
Map<Dish.Type, Optional<Dish>> mostCaloricByType = menu.stream().collect(
groupingBy(
Dish::getType,
maxBy(comparingInt(Dish::getCalories))));
// 결과값
{FISH= Optional[salmon], OTHER=Optional[pizza], MEAT=Optional[pork]}- 컬렉터 결과를 다른 형식에 적용하기 마지막 그룹화 연산에서 맵의 모든 값을 Optional로 감쌀 필요가 없으므로 Optional을 삭제할 수 있다.
Map<Dish.Type, Optional<Dish>> mostCaloricByType2 =
menu.stream()
.collect(groupingBy(Dish::getType, // 분류 함수
maxBy(comparingInt(Dish::getCalories))));
// {OTHER=Optional[pizza], FISH=Optional[salmon], MEAT=Optional[pork]}
// maxBy가 생성하는 컬렉터결과값이 Optional임
/*
public static <T> Collector<T, ?, Optional<T>> maxBy(Comparator<? super T> comparator) {
return reducing(BinaryOperator.maxBy(comparator));
}
*/
Map<Dish.Type, Dish> mostCaloricByType =
menu.stream()
.collect(groupingBy(Dish::getType, // 분류 함수
collectingAndThen(
maxBy(comparingInt(Dish::getCalories)), // 감싸인 컬렉터
Optional::get // 변환 함수
)));
// {OTHER=pizza, FISH=salmon, MEAT=pork}팩토리 메서드 collectingAndThen은 적용할 컬렉터와 변환 함수를 인수로 받아 다른 컬렉터를 반환한다.
반환되는 컬렉터는 기존 컬렉터의 래퍼 역활을 하며 collect의 마지막 과정에서 변환함수로 자신이 반환하는 값을 매핑한다.
그럼 위의 코드가 실제로 어떤 과정을 거치는지 확인해보자

- 컬렉터는 점선으로 표시되어 있으며 groupingBy는 가장 바깥쪽에 위치하면서 요리의 종류에 따라 메뉴 스트림을 세 개의 서브스트림으로 그룹화한다.
- groupingBy 컬렉터는 collectingAndThen 컬렉터를 감싼다. 따라서 두 번째 컬렉터는 그룹화된 세 개의 서브스트림에 적용된다.
- collectingAndThen 컬렉터는 세 번째 컬렉터 maxBy를 감싼다
- 리듀싱 컬렉터가 서브스트림에 연산을 수행한 결과에 collectingAndthen의 Optional::get 변환 함수가 적용된다.
- groupingBy 컬렉터가 반환하는 맵의 분류 키에 대응하는 세 값이 각각의 요리 형식에서 가장 높은 칼로리다.
- groupingBy와 함께 사용하는 다른 컬렉터 예제
- 일반적으로 스트림에서 같은 그룹으로 분류된 모든 요소에 리듀싱 작업을 수행할 때는 팩토리 메서드 groupingBy에 두 번째 인수로 전달한 컬렉터를 사용한다.
- 모든 요리의 칼로리 합계를 구하려고 만든 컬렉터를 재사용할 수 있다.
Map<Dish.Type, Integer> totalCaloriesByType= menu.stream().collect(
groupingBy(Dish::getType,
summingInt(Dish::getCalories)));mapping 메서드는 스트림의 인수를 변환하는 함수와 변환 함수의 결과 객체를 누적하는 컬렉터를 인수로 받는다.
mapping은 입력 요소를 누적하기 전에 매핑 함수를 적용해서 다양한 형식의 객체를 주어진 형식의 컬렉터에 맞게 변환하는 역할을 한다.
Map<Dish.Type, Set<CaloricLevel>> dishesByTypeCaloricLevel =
menu.stream().collect(
groupingBy(Dish::getType,
mapping(dish -> {
if (dish.getCalories() <= 400) {
return CaloricLevel.DIET;
} else if (dish.getCalories() <= 700) {
return CaloricLevel.NORMAL;
} else {
return CaloricLevel.FAT ;
}
},
toSet())));
// 결과값
{
MEAT={DIET, NORMAL, FAT},
FISH={DIET, NORMAL},
OTHER={DIET, NORMAL}
}mapping 메서드에 전달한 변환 함수는 Dish를 CaloricLevel로 매핑한다.
그리고 CaloricLevel 결과 스트림은 (toList와 비슷한) toSet 컬렉터로 전달되면서
리스트가 아닌 집합으로 스트림의 요소가 누적된다(따라서 중복된 값은 저장되지 않는다)
- 분할 분할은 분할 함수라 불리는 Predicate를 분류 함수로 사용하는 특수한 그룹화 기능이다.
분할 함수는 Boolean을 반환하므로 맵의 키 형식은 Boolean이다.
결과적으로 그룹화 맵은 최대(참 아니면 거짓의 값을 갖는) 두 개의 그룹으로 분류된다.
Map<Boolean, List<Dish> partitionedMenu = menu.stream().collect(partitioningBy(Dish::isVegetarian));
// 결과값
{
false = [pork, beef, chicken, prawns, salmon],
true = [french fries, rice, season fruit, pizza]
}
partitionedMenu.get(true);
// 결과값
[french fries, rice, season fruit, pizza]List<Dish> vegeterianDishes = menu.stream()
.filter(Dish::isVegetarian)
.collect(toList());
// 결과값
[french fries, rice, season fruit, pizza]- 분할의 장점 분할 함수가 반환하는 참, 거짓 두 가지 요소의 스트림 리스트를 모두 유지한다는 것이 분할의 장점이다.
다음 코드에서 보여주는 것처럼 컬렉터를 두 번째 인수로 전달할 수 있는 오버로드된 버전의 partitioningBy 메서드도 있다.
Map<Boolean, Map<Dish.Type,List<Dish>>> vegetarianDishesByType =
menu.stream().collect(
partitioningBy(Dish::isVegetarian,
groupingBy(Dish::getType)));
// 결과값
{
false = {FISH=[prawns, salmon], MEAT=[pork, beef, chicken]},
true = {OTHER=[french fries, rice, season fruit, pizza]}
}- 요약 collect는 스트림의 요소를 요약 결과로 누적하는 다양한(컬렉터라 불리는)을 인수로 갖는 최종 연산이다.
스트림의 요소를 하나의 값으로 리듀스하고 요약하는 컬렉터뿐 아니라 최솟값, 최댓값, 평균값을 계산하는 컬렉터 등이 미리 정의되어 있다.
미리 정의된 컬렉터인 groupingBy로 스트림의 요소를 그룹화하거나, partitioningBy로 스트림의 요소를 분할할 수 있다.
컬렉터는 다수준의 그룹화, 분할, 리듀싱 연산에 적합하게 설계되어 있다.
Collector 인터페이스에 정의된 메서드를 구현해서 커스텀 컬렉터를 개발할 수 있다.
Collectors 클래스에 존재하는 정적 팩토리 메서드
(https://docs.oracle.com/javase/8/docs/api/java/util/stream/Collectors.html)

public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
BinaryOperator<A> combiner();
Function<A, R> finisher();
Set<Characteristics> characteristics();
}T는 수집될 항목의 제네릭 형식이다.
A는 누적자, 즉 수집 과정에서 중간 결과를 누적하는 객체의 형식이다.
R은 수집 연산 결과 객체의 형식이다.
예를 들어 Stream의 모든 요소를 List로 수집하는 ToListCollector라는 클래스는 아래와 같이 만들 수 있다.
public class ToListCollector<T> implements Collector<T, List<T>, List<T>>- supplier 메서드 : 새로운 결과 컨테이너 만들기
- supplier 메서드는 수집 과정에서 빈 누적자 인스턴스를 만드는 파라미터가 없는 함수이다.
- accumulator 메서드 : 결과 컨테이너에 요소 추가하기
- accumulator 메서드는 리듀싱 연산을 수행하는 함수를 반환한다. 즉 누적자(스트림의 첫 n-1개 항목을 수집한 상태)와 n번째 요소를 함수에 적용한다 (그렇기에 제네릭 형식도 <A, T>이다).
- finisher 메서드 : 최종 변환값을 결과 컨테이너로 적용하기
- finisher 메서드는 스트림 탐색을 끝내고 누적자 객체를 최종 결과로 반환하면서 누적 과정을 끝낼 때 호출할 함수를 반환해야 한다. ToListCollector와 같이 누적자 객체가 이미 최종 결과인 상황도 있다. 이럴 경우 finisher함수는 항등 함수를 반환한다.
- combiner 메서드 : 두 결과 컨테이너 병합
- combiner는 스트림의 서로 다른 서브 파트를 병렬로 처리할 때 누적자가 이 결과를 어떻게 처리할지 정의한다 (그렇기에 BinaryOperator이다).
- characteristics 메서드
- characteristics 메서드는 컬렉터의 연산을 정의하는 Characteristics 형식의 불변 집합을 반환한다.
enum Characteristics {
CONCURRENT,
UNORDERED,
IDENTITY_FINISH
}- UNORDERED : 리듀싱 결과는 스트림 요소의 방문 순서나 누적 순서에 영향을 받지 않는다.
- CONCURRENT : 다중 스레드에서 accumulator 함수를 동시에 호출할 수 있으며 병렬 리듀싱을 수행할 수 있다. 컬렉터의 플래그에 UNORDERED를 함께 설정하지 않았다면 데이터 소스가 정렬되어 있지 않은 상황에서만 병렬 리듀싱을 수행할 수 있다.
- IDENTITY_FINISH : finisher 메서드가 반환하는 함수는 단순히 identity를 적용할 뿐이므로 이를 생략할 수 있다. 따라서 리듀싱 과정의 최종 결과로 누적자 객체를 바로 사용할 수 있다. 또한 누적자 A를 결과 R로 안전하게 형 변환할 수 있다.
ToListCollector 구현 예시
public class ToListCollector<T> implements Collector<T, List<T>, List<T>> {
@Override
public Supplier<List<T>> supplier() {
return ArrayList::new;
}
@Override
public BiConsumer<List<T>, T> accumulator() {
return List::add;
}
@Override
public BinaryOperator<List<T>> combiner() {
return (list1, list2) -> {
list1.addAll(list2);
return list1;
};
}
@Override
public Function<List<T>, List<T>> finisher() {
return Function.identity();
}
@Override
public Set<Characteristics> characteristics() {
return Collections.unmodifiableSet(EnumSet.of(
IDENTITY_FINISH, CONCURRENT));
}
}
'Study > Modern-Java-In-Action' 카테고리의 다른 글
| Modern Java Ch08. 컬렉션 API 개선 (0) | 2023.01.24 |
|---|---|
| Modern Java Ch07. Stream 병렬 처리와 성능 (0) | 2023.01.21 |
| Modern Java Ch05. Stream 활용 (0) | 2023.01.20 |
| Modern Java Ch04. Stream 소개 (0) | 2023.01.19 |
| Modern Java Ch03. Lambda (0) | 2023.01.19 |
댓글