Modern Java Ch15. completableFuture와 Reactive 프로그래밍
CompletalbeFuture와 리액티브 프로그래밍 컨셉의 기초
- Thread, Future, 자바가 풍부한 동시성 API를 제공하도록 강요하는 진화의 힘
- 비동기 API
- 동시 컴퓨팅의 박스와 채널 뷰
- CompletableFuture 콤비네이터로 박스를 동적으로 연결
- 리액티브 프로그램용 자바 9 플로 api의 기초를 이루는 발행 구독 프로토콜
- 리액티브 프로그래밍과 리액티브 시스템
- 포크/조인 프레임워크
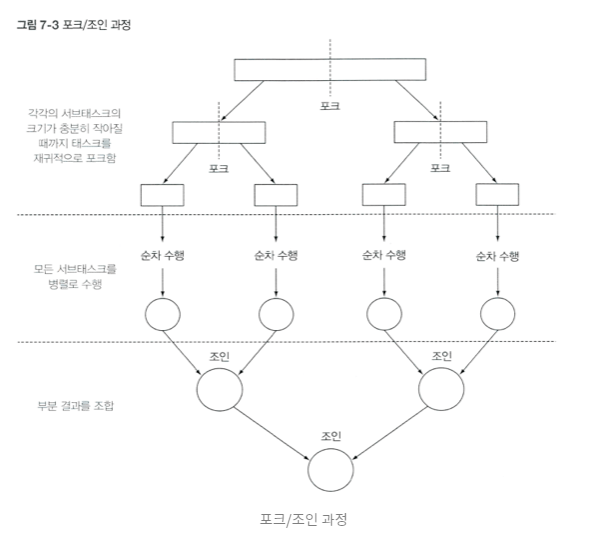
- 병렬화할 수 있는 작업을 재귀적으로 작은 작업으로 분할한 다음에 서브태스크 각각의 결과를 합쳐서 전체 결과를 만들도록 설계되었다.
- 하나의 작업을 작은 단위로 나눠서 여러 쓰레드가 동시에 처리하는 것을 쉽게 만들어 준다.
- 분할 정복 (divide and conquer) 알고리즘의 병렬화 버전이다.
- 분할 정복 알고리즘
- 문제를 나눌 수 없을 때까지 나누어서 각각을 풀면서 다시 합병하여 문제의 답을 얻는 알고리즘이다.
- 알고리즘을 설계하는 요령
- Divide : 문제가 분할이 가능한 경우, 2개 이상의 문제로 나눈다.
- Conquer : 나누어진 문제가 여전히 분할이 가능하면, 또 다시 Divide를 수행한다. 그렇지 않으면 문제를 푼다.
- Combine : Conquer한 문제들을 통합하여 원래 문제의 답을 얻는다.

정렬하면서 합치는 방법 :

포크/조인 프레임워크에서는 서브태스크를 스레드 풀(ForkJoinPool)의 작업자 스레드에 분산 할당하는 ExecutorService 인터페이스를 구현한다.
- RecursiveTask 활용 스레드 풀을 이용하려면 RecursiveTask 의 서브클래스를 만들어야 한다.
여기서 R은 병렬화된 태스크가 생성하는 결과 형식 또는 결과가 없을 때는 RecursiveAction 형식이다.
RecursiveTask를 정의하려면 추상 메서드 compute를 구현해야 한다.
protected abstract R compute();
compute 메서드는 태스크를 서브태스트로 분할하는 로직과 / 더 이상 분할할 수 없을 때 개별 서브태스크의 결과를 생산할 알고리즘을 정의한다.
따라서 대부분의 compute 메서드 구현은 다음과 같은 형식을 유지한다.
if (태스크가 충분히 작거나 더 이상 분할할 수 없으면) {
순차적으로 태스크 계산(알고리즘)
} else {
태스크를 두 서브태스크로 분할(재귀적 호출, Fork)
모든 서브태스크의 연산이 완료될 때까지 기다림
각 서브태스크의 결과를 합칩(Join)
}
일반적으로 애플리케이션에서는 둘 이상의 ForkJoinPool을 사용하지 않는다.
즉, 소프트웨어의 필요한 곳에서 언제든 가져다 쓸 수 있도록 ForkJoinPool을 한 번만 인스턴스화해서 정적 필드에 싱글턴으로 저장한다.
ForkJoinPool의 인스턴스를 생성하면서 인수가 없는 기본 생성자를 이용했는데, 이는 JVM에서 이용할 수 있는 모든 프로세서가 자유롭게 풀에 접근할 수 있음을 의미한다.
package com.example.demo;
import java.util.concurrent.RecursiveTask;
public class SumCalculator extends RecursiveTask<Long> {
private final long[] numbers; // 더할 숫자 배열
private final int start; // 배열 초기 위치
private final int end; // 배열 최종 위치
private static final long THRESHOLD = 10; // 서브태스크 분할 최소 기준값
// 해당 클래스를 생성할때 사용할 공개 생성자
public SumCalculator(long[] numbers) {
this(numbers, 0, numbers.length);
}
// 재귀 호출을 위한 비공개 생성자
private SumCalculator(long[] numbers, int start, int end) {
this.numbers = numbers;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
// 이 태스크에서 처리할 길이
int length = end - start;
// 최소 기준값 이하 시 결과 계산
if (length <= THRESHOLD)
return computeSequentially();
// 배열 길이의 반
int halfLength = start + length / 2;
// 배열의 길이를 절반으로 나누어 태스크로 분할
System.out.println("재귀 분할!");
// 왼쪽 태스크
SumCalculator leftTask = new SumCalculator(numbers, start, halfLength);
leftTask.fork(); // 왼쪽 태스크는 다른 스레드로 태스크를 비동기로 실행
// 오른쪽 태스크
SumCalculator rightTask = new SumCalculator(numbers, halfLength, end);
Long rightResult = rightTask.compute(); // 오른쪽 태스크는 재귀함수 호출
Long leftResult = leftTask.join(); // 왼쪽 태스크의 결과를 읽거나 아직 결과가 없으면 기다림
return leftResult + rightResult; // 왼쪽 태스크 결과 + 오른쪽 태스크 결과
}
private long computeSequentially() {
System.out.println("숫자 더하기!");
long sum = 0;
for (int i = start; i < end; i++) {
sum += numbers[i];
}
return sum;
}
}
최근 개발방법을 획기적으로 변화하게 만든 두가지 추세가 있다.
- 하나는 병렬실행 2. 두번째는 마이크로서비스 아키텍처 이다.
멀티코어 프로세서가 발전하면서 애플리케이션 속도는
멀티코어 프로세서를 활용할 수 있도록 소프트웨어를 개발하는가에 따라 달라질 수 있다.
한개의 큰 태스크를 개별 하위태스크로 분리해 병렬로 실행할 수 있고,
포크/조인 프레임워크 나 병렬스트림으로 병렬실행을 달성할 수 있다.
마이크로서비스로 인해 서비스가 작아진 대신 네트워크 통신이 증가했다.
공개 API를 통해 더 많은 인터넷 서비스를 접할수 있게 되었고,
독립적으로 동작하는 웹사이트나 네트워크 애플리케이션을 찾아보기 힘들다.
앞으로는 다양한 소스의 콘텐츠를 가져와 합쳐서 만드는 메시업 mashup 형태의 웹 애플리케이션이 많이 등장할 것이다.
여러 웹서비스에 접근해서 데이터를 가져오며 기다리는 동안 다른 웹서비스 데이터를 처리하려면 어떻게 해야할까?
동시성을 필요로 하는 상황에서 연관된 작업을 같은 CPU에서 동작하도록 하려면?

동시성과 병렬성
동시성 은 단일 코어 머신에서 발생할 수 있는 프로그램잉 속성으로 실행이 겹칠 수 있는 반면
병렬성 은 병렬 실행을 하드웨어 수준에서 지원한다.
15.1 동시성을 구현하는 자바 지원의 진화
자바 초반 Runnable과 Thread를 동기화된 클래스와 메서드 잠금을 이용했다.
이후 스레드 실행과 태스크 제출을 분리하는 ExecutorService 인터페이스,
Runnable, Thread의 변형을 반환하는 Callable, Future, 제네릭 등을 지원했다.
자바 7에서는 포크/조인 프레임워크를 이용하거나
자바8에서는 스트림과 새로 추가된 람다에 기반한 병렬 프로세싱이 추가되었다.
자바9에서는 분산 비동기 프로그래밍을 지원하는데, 매쉬업 어플리케이션을 개발하는데 기초 모델과 툴킷을 제공한다.
이 과정을 리액티브 프로그래밍이라 부른다.
궁극적인 목표는 동시에 실행할 수 있는 독립적인 태스크를 가능하게 만들며, 멀티코어 또는 기기를 통해 제공되는 병렬성을 쉽게 이용하는 것이다.
executorService 인터페이스는 Executor 인터페이스를 상속받으며 Callable을 실행하는 submit이라는 메서드를 포함한다.
Exector 인터페이스는 Runnable을 실행할 수 있는 execute 메서드만 포함한다.
1 - 스레드와 높은 수준의 추상화
프로세스는 운영체제에 한 개 이상의 스레드
즉, 본인이 가진 프로세스와 같은 주소 공간을 공유하는 프로세스를 요청해 태스크를 동시에 또는 협력적으로 실행할 수 있다.
각 코어는 한개 이상의 프로세스나 스레드에 할당될 수 있지만 프로그램이 스레드를 사용하지 않으면
- 코어란 : CPU의 핵심적인 역할을 수행해내는 중심부 역할을 말하며 이 코어에서 시스템의 모든 연산을 처리한다고 보면 되겠다. 효율을 고려해 여러 프로세서 코어 중 한개만을 사용할 것이다.
병렬 스트림 반복은 명시적으로 스레드를 사용하는 것에 비해 높은 수준의 개념이라는 사실을 알 수 있다. 스트림을 이용해 스레드 패턴을 추상화할 수 있다. 쓸모 없는 코드가 라이브러리 내부로 구현되면서 복잡성도 줄어든다는 장점이 더해진다.
2 - Executor와 스레드 풀
- 스레드의 문제 자바 스레드는 직접 운영체제 스레드에 접근한다.
운영체제 스레드를 만들고 종료하려면 비싼 비용을 치러야 하며 더욱이 운영체제 스레드의 숫자는 제한되어 있는 것이 문제다.
운영체제가 지원하는 스레드 수를 초과해 사용하면 자바 애플리케이션이 예상치 못한 방싯으로 크래시될 수 있으므로
기존 스레드가 실행되는 상태에서 계속 새로운 스레드를 만드는 상황이 일어나지 않도록 주의해야 한다.
- 스레드 풀 그리고 스레드 풀이 더 좋은 이유
자바 ExecuorService는 task를 제출하고 나중에 수집할 수 있는 인터페이스를 제공한다.
newFixedThreadPool 같은 팩토리 메서드 중 하나를 이용해 스레드 풀을 만들어 사용할 수 있다.
ExecutorService newFixedThreadPool(int nThreads)이 메서드는 워커 스레드라 불리는 nThreads를 포함하는 ExecutorService를 만들고 이들을 스레드 풀에 저장한다.
스레드 풀에서 사용하지 않은 스레드로 제출된 태스크를 먼저 온 순서대로 실행한다.
태스크 실행이 종료되면 이들 스레드를 풀로 반환한다.
- 장점 : 하드웨어에 맞는 수의 태스크를 유지함과 동시에 수 천개의 태스크를 스레드 풀에 아무 오버헤드 없이 제출할 수 있다는 점이다.
프로그래머는 task (Runnable이나 Callable)를 제공하면 스레드가 이를 실행한다.
<br><br><br>
- 스레드 풀 그리고 스레드 풀이 나쁜이유
주의해야할 두가지 k스레드를 가진 스레드 풀은 오직 k만큼의 스레드를 동시에 실행할 수 있다. 초과로 제출된 테스크는 큐에 저장되며 이전의 taxk 중 하나가 종료되기 전까지는 스레드에 할당하지 않는다.
1. 이때 스레드에서 실행중인 테스크가 IO요청을 기다리면서 블록 상황이 생기면 스레드 수가 줄게 된다. 블록 할 수 있는 task는 스레드 풀에 제출하지 말아야 한다. 2. 프로그램을 종료하기 전에 모든 스레드 풀을 종료하는 습관이 중요하다.
3 - 스레드의 다른 추상화 : 중첩되지 않은 메서드 호출
7장에서 설명한 동시성은 한 개의 특별한 속성
즉, 태스크나 스레드가 메서드 호출 안에서 시작되면 그 메서드 호출은 반환하지 않고 작업이 끝나기를 기다렸다.
스레드 생성과 join()이 한 쌍처럼 중첩된 메서드 호출 내에 추가되었다. => 엄격한 포크 조인

엄격한 포크조인 이미지
화살표는 스레드, 원은 포크와 조인, 사각형은 메서드 호출과 반환

여유로운 포크/조인
15장에서는 사용자의 메서드 호출에 의해 스레드가 생성되고 메서드를 벗어나 계속 실행되는 동시성 형태이다.
그러나 이들 메서드 사용 시에 어떤 위험성이 따른다.
- 스레드 실행은 메서드를 호출한 다음의 코드와 동시에 실행되므로 데이터 경쟁 문제를 일으키지 않도록 주의해야 한다.
- 기존 실행 중이던 스레드가 종료되지 않은 상황에서 자바의 main() 메서드가 반환되면?
- 애플리케이션을 종료하지 못하소 모든 스레드가 실행을 끝낼때까지 기다린다.
- 애플리케이션 종료를 방해하는 스레드를 강제종료 시키고 애플리케이션을 종료한다.
1번째 방법은 종료를 못한 애플리케이션이 크래시될 수 있다.
자바 스레드는 setDaemon을 이용해 데몬/비데몬으로 구분시킬 수 있다.
main() 메서드는 모든 비데몬 스레드가 종료될 때까지 프로그램을 종료하지 않고 기다린다.
4 - 스레드에 무엇을 바라는가?
모든 하드웨어 스레드를 활용해 병렬성의 장점을 극대화하도록 프로그램 구조를 만드는 것, 프로그램을 작은 태스크 단위로 구조화 하는것이 목표다.
15.2 동기 API 와 비동기 API
외부반복(명시적 for 루프) 을 내부반복(스트림 메서드 사용)으로 바꿔야 한다.
루프가 실행될때 런타임 시스템은 사용할 수 있는 스레드를 더 정확하게 알고 있다는게 내부반복의 장점이다.
ex) 다음과 같은 시그니처를 갖는 f,g 두 메서드의 호출을 합하는 예제
int f(int x);
int g(int x);
별도의 스레드로 f와 g를 실행해 구현했지만 코드가 복잡해졌다.
class ThreadExample {
public static void main(String[] args) throws InterruptedException {
int x = 1337;
Result result = new Result();
Thread t1 = new Thread(() -> { result.left = f(x); } );
Thread t2 = new Thread(() -> { result.right = g(x); });
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(result.left + result.right);
}
private static class Result {
private int left;
private int right;
}
}Runnable 대시 Future API 인터페이스를 이용해 코드를 단순화 할 수 있다.
public class ExecutorServiceExample {
public static void main(String[] args)
throws ExecutionException, InterruptedException {
int x = 1337;
ExecutorService executorService = Executors.newFixedThreadPool(2);
Future<Integer> y = executorService.submit(() -> f(x));
Future<Integer> z = executorService.submit(() -> g(x));
System.out.println(y.get() + z.get());
executorService.shutdown();
}
}
하지만 submit 메서드 호출같은 불필요한 메서드 처리가 남았다.
이는 비동기 API라는 기능으로 API를 바꿔서 해결할 수 있다.
1 - Future 형식 API
시그니처를 바꾸고
Future<Integer> f(int x);
Future<Integer> g(int x);
호출을 바꿀수 있다.
Future<Integer> y = f(x);
Future<Integer> z = g(x);
System.out.println(y.get() + z.get());
동기 API는 보통 결과가 나올 때까지 물리적인 반환을 지연시킴으로 블록킹 API로도 알려져있다. 반면 비동기 API는 블록하지 않는 I/O를 구현한다. EX) Netty
2 - 리액티브 형식 API
f,g의 시그니처를 바꿔서 콜백 형식의 프로그래밍을 이용하는 것이다.
void f(int x, IntConsumer dealWithResult);
f에 추가 인수로 콜백(람다)를 전달해서 f의 바디에서는 return문으로 결과를 반환하는 것이 아니라
결과가 준비되면 이를 람다로 호출하는 task를 만드는 것이 비결이다.
= f는 바디를 실행하면서 태스크를 만든 다음 즉시 반환하므로 코드 형식이 다음처럼 바뀐다.
public class CallbackStyleExample {
public static void main(String[] args) {
int x = 1337;
Result result = new Result();
f(x, (int y) -> {
result.left = y;
System.out.println((result.left + result.right));
} );
g(x, (int z) -> {
result.right = z;
System.out.println((result.left + result.right));
});
}
}- 리액티브 형식의 API는 보통 한 결과가 아니라 일련의 이벤트에 반응하도록 설계되었으므로 Future를 이용하는것이 적절
하지만 결과가 달라진다.ㅠㅠ
f와 g 중 호출 합계를 정확하게 출력하지 않고 상황에 따라 먼저 계산된 결과가 출력된다.
락을 사용하지 않으므로 값을 두 번 출력할 수 있을 뿐더러 때로는 +에 제공된 두 피연산자가 println이 호출되기 전에 업데이트 될 수도 있다.
- 일부 저자는 콜백이라는 용어를 Stream.filter, Stream.map처럼 메서드 인수로 넘겨지는 인수로 넘겨지는 모든 람다나 메서드 참조를 가리키는 데 사용한다. 이 책에서는 메서드가 반환된 다음에 호출될 수 있는 람다나 메서드 참조를 가리키는 용어로 사용한다.
3 - 잠자기(그리고 기타 블로킹 동작)는 해로운 것으로 간주
스레드는 sleep()메서드로 잠들어도 여전히 시스템자원을 점유한다.
블록동작은 다른 태스크가 어떤 동작을 완료하기를 기다리는 동작과 외부 상호작용을 기다리는 동작 두가지로 구분.
-> 태스크 앞과 뒤 두 부분으로 나누고 블록되지 않을때만 뒷부분을 자바가 스케줄링하도록 요청
태스크를 블록하는것보다는 다음 작업을 태스크로 제출하고 현재 태스크는 종료하는것이 좋다.
스레드에는 제한이 있고 저렴하지 않으므로 잠을 자거나 블록해야하는 여러 태스크가 있을때 가능하면 다음의 형식을 따르자.
//기존 코드
work1();
Thread.sleep(10000);
work2();//work2를 task로 제출
public class ScheduledExecutorServiceExample {
public static void main(String[] args) {
ScheduledExecutorService scheduledExecutorService
= Executors.newScheduledThreadPool(1);
work1();
scheduledExecutorService.schedule(
ScheduledExecutorServiceExample::work2, 10, TimeUnit.SECONDS); //work1이 끝난 다음 10초 뒤에 work2를 개별 task로 스케줄함
scheduledExecutorService.shutdown();
}
public static void work1(){
System.out.println("Hello from Work1!");
}
public static void work2(){
System.out.println("Hello from Work2!");
}
}위와 아래 코드의 차이점은 a가 자는 동안 귀중한 스레드 자원을 점유하는 반면 b는 다른 작업이 실행될 수 있도록 허용한다는 점이다.
스레드를 사용할 필요가 없이 메모리만 조금 더 사용했다.
4 - 현실성 확인
시스템을 많은 작은 동시 실행되는 태스크로 설계해서 블록할 수 있는 모든 동작을 비동기 호출로 구현한다면 병렬 하드웨어를 최대한 활용할 수 있다.
하지만 현식적으로 '모든것은 비동기' 설계원칙을 어겨야 한다.
개선된 동시성 API 사용을 권장한다.
네트워크 서버의 블록/비블록 API를 일관적으로 제공하는 Netty같은 라이브러리 사용도 도움이 된다.
5 - 비동기 API에서 예외는 어떻게 처리하는가?
Futrue나 리액티브 형식의 비동기 API에서 호출된 메서드의 실제 바디는 별도의 스레드에서 호출되며
이때 발생하는 에러는 실행범위와 관계없는 상황이 되버린다.
Future를 구현한 CompletableFuture에서는 런타임 get() 메서드에 예외를 처리할 수 있는 기능을 제공하고
예외에서 회복할 수 있게 exceptionally() 메서드도 제공한다.
리액티브 형식의 비동기 API의 경우 호출된 콜백에서 예외발생시 실행할 추가 콜백도 만들어주자.
void f(int x, Consumer dealWithResult, Consumer dealWithException);
콜백이 여러개면 이를 따로 제공하는것보다 한 객체로 이 메서드를 감싸는것이 좋다.
자바9 API에서 여러 콜백을 한 객체 Subscriber클래스 를 만들었다.
void onComplete()
void onError(Throwable throwable)
void onNext(T item) 바뀐 시그니처
void f(int x, Subscriber s);
15.3 박스와 채널 모델
박스와 채널모델로 생각과 코드를 구조화 할 수 있고, 대규모 시스템 구현의 추상화 수준을 높일 수 있다.
p함수에 인수 x를 이용해 호출하고 그 결과를 q1, q2에 전달하며 이 두 호출의 결과로 함수 r을 호출한 다음 결과를 출력한다.

// 하드웨어 병렬성과 거리가 먼 코드
int t = p(x);
System.out.println( r(q1(t), q2(t)) );
// Future를 이용해 f,g를 병렬로 평가하는 방법
int t = p(x);
Future<Integer> a1 = executorService.submit(() -> q1(t));
Future<Integer> a2 = executorService.submit(() -> q2(t));
System.out.println( r(a1.get(),a2.get()));
p는 다름 어떤 작업보다 먼저 처리해야 하며 r은 모든 작업이 끝난 다음 가장 마지막으로 처리해야 한다. 따라서 p와 r은 Future로 감싸지 않았다.
병렬성을 극대화하려면 (p, q1, q2, r, s)를 Future로 감싸야 한다.
많은 태스크가 get() 메서드를 호출해 Future가 끝나기를 기다리는 상태에 놓일수 있다.
시스템 구조가 얼마나 많은 수의 get()을 감당할 수 있을지 예측하기 어려움.
자바8에서는 CompletableFuture와 콤비네이터를 이용해 해결할 수 있다.
####### 15.4 CompletableFuture와 콤비네이터를 이용한 동시성
일반적으로 Future는 실행해서 get()으로 결과를 얻을 수 있는 Callable로 만들어진다.
CompletableFuture는 실행할 코드 없이 Future를 만들 수 있게 허용하며
complete() 메서드를 이용해 나중에 어떤 값을 이용해 다른 스레드가 이를 완료할 수 있고
get()으로 값을 얻을 수 있게 허용한다.
public class CFComplete {
public static void main(String[] args)
throws ExecutionException, InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(10);
int x = 1337;
CompletableFuture<Integer> a = new CompletableFuture<>();
executorService.submit(() -> a.complete(f(x)));
int b = g(x);
System.out.println(a.get() + b);
executorService.shutdown();
}
}
// 또는 다음과 같이 구현
public class CFComplete {
public static void main(String[] args)
throws ExecutionException, InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(10);
int x = 1337;
CompletableFuture<Integer> a = new CompletableFuture<>();
executorService.submit(() -> b.complete(g(x)));
int a = f(x);
System.out.println(a + b.get());
executorService.shutdown();
}
}하지만 f(x)나 g(x)의 실행이 끝나지 않으면 get()을 기다려야 하므로 프로세싱 자원 낭비할 수 있다.
CompletableFuture을 사용하면 이를 해결할 수 있다. --> 16장에서 더 자세히 다룸
CompletableFuture thenCombine(CompletableFuture other, BiFunction<T, U, V> fn)
(T ,U)두개 CompletableFuture 값을 받아 새 값을 만든다
thenComine 메서드를 사용해 두 연산 결과를 효과적으로 연결
처음 두 작업이 끝나면 두 결과 모두에 fn을 적용하고 블록하지 않은 상태로 결과 Future를 반환.
public class CFCombine {
public static void main(String[] args) throws ExecutionException,
InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(10);
int x = 1337;
CompletableFuture<Integer> a = new CompletableFuture<>();
CompletableFuture<Integer> b = new CompletableFuture<>();
CompletableFuture<Integer> c = a.thenCombine(b, (y, z)-> y + z);
executorService.submit(() -> a.complete(f(x)));
executorService.submit(() -> b.complete(g(x)));
System.out.println(c.get());
executorService.shutdown();
}
}thenCombine절이 핵심이다.
######### 15.6 발행 - 구독 그리고 리액티브 프로그래밍 Future와 CompletableFuture는 독립적 실행과 병렬성이라는 정식적 모델에 기반한다.
따라서 Future는 한번만 실행해 결과를 제공한다.
스트림은 선형적 파이프라인 처리 기법에 알맞다.
- 발행-구독 패턴(Publisher-Subscriber Pattern)이란?

발행구독 패턴은, 비동기 메시징 패러다임이다.
발행자와 구독자가 있고, 그 사이에 브로커(=메시지 큐)가 존재하는 형태이다.
이것의 특징을 요약하면,
- 발행자 메시지의 수신자가 정해져 있지 않다.
- 메시지는 정해진 범주에 따라서 구독을 신청한 수신자에게 전달이 된다.
- 수신자는 발행자에 대한 정보 없이, 원하는 메시지를 수신할 수 있다.
- 메시지 큐 패러다임과 마치 형제같은 관계로, 대형 메시지 지향 미들웨어 솔루션의 일부라고 한다.
- 발행자와 구독자
발행자(=pub)와 구독자(=sub)는 다음과 같은 특징을 가진다.
- pub이 sub의 선언 위치나 존재를 알 필요가 없다.
메시지 큐와 같은 브로커 역할을 하는 중간 지점에 메시지를 던져 두기만 하면, 브로커가 알아서 처리한다. - sub 역시 pub의 선언 위치나 존재를 알 필요가 없다.
브로커에 할당된 작업만을 모니터링하고, 원하는 작업이 발생하면 할당받아 작업을 수행하면 된다.
그러므로 pub, sub은 서로 알 필요가 없으며, 브로커와의 통신만을 수행할 수 있다면 역할을 잘 수행하는 것이다.
- 브로커
브로커는 발행자와 구독자 사이에 위치하고 있다.
주로 메시지큐가 브로커로서의 역할을 수행하며, 두 객체 사이에서 구독과 발행 이후의 메시지를 처리해준다.
즉, 브로커가 모든 들어오는 메시지를 필터링하며, 타겟들(=구독자)에게 메시지를 배포하는 역할을 한다.
이는, 메시지 지향 미들웨어(MOM = Message Oriented Middleware)를 구현한 시스템을 의미한다.
여기서 MOM이란? 비동기 메시지를 사용하는 응용 프로그램 간 데이터 송수신을 의미한다.
공정 작업 연기가 가능한 유연성을 제공하며, SOA(Service Oriented Architecture) 개발에 도움을 준다.
메시지 큐의 장점은 다음과 같다.
비동기(Asynchronous) : 큐에 넣어서 나중에 처리 가능
비동조(Decoupling) : 앱과 분리 가능
탄력성(Resilience) : 일부 실패가 전체에 영향x
과잉(Redunadancy) : 실패할 경우 재실행 가능
보증(Guarantees) : 작업 처리 확인 가능
확장성(Scalable) : 다수 프로세스들이 큐에 메시지 보내기 가능
메시지 큐의 단점은 다음과 같다.
'큐'이기 때문에 사용자가 많아지거나, 데이터가 많아지면 요청에 대한 응답이 늦어지게 된다.
즉 과도한 트래픽이 몰리게 되면, 대기 시간 지연으로 인해 서비스가 망가질 위험이 있다.
메시지 큐의 사용 예시는 다음과 같다.
다른 곳의 API로부터 데이터 송수신이 가능하다.
다양한 앱과 비동기 통신이 가능하다.
이메일 발송, 문서 업로드가 가능하다.
많은 양의 프로세스를 처리 가능하다.
옵저버 패턴과 함께 발행구독 패턴 이해하기 옵저버 패턴과 발행구독 패턴은 매우 유사하지만, 분명한 차이점이 존재한다.
가장 큰 차이는 발행구독 패턴은 옵저버와 옵저버블 사이에 브로커(= 메시지 큐, 이벤트 버스)라고 불리는 중개자가 존재한다는 것이다.
'Study > Modern-Java-In-Action' 카테고리의 다른 글
| Modern Java Ch17. Reactive Programming 이해하기 (1) | 2023.01.29 |
|---|---|
| Modern Java Ch16. 안정적 비동기 프로그래밍 (0) | 2023.01.29 |
| Modern Java Ch13. Default Method (0) | 2023.01.24 |
| Modern Java Ch12. 날짜와 시간 API (0) | 2023.01.24 |
| Modern Java Ch11. Optional Class (0) | 2023.01.24 |
댓글