Study/AI
[LangChain] 검색기, Retriever 개념. similarity_search와 차이점
728x90
반응형
저장된 벡터 데이터베이스에서 사용자의 질문과 관련된 문서를 검색하는 과정. 이 단계는 사용자 질문에 가장 적합한 정보를 신속하게 찾아내는 것이 목표이며, RAG 시스템의 전반적인 성능과 직결되는 매우 중요한 과정이다.
벡터스토어에 직접 질의를 해서 코사인 유사도에 따라 k개의 문서를 찾아서 문서 리스트 List[Document]를 반환한다. 단순 검색 기능만 제공하고, 추가 체인 연결이나 확장성을 고려하지 않는다.
LangChain 전체에서 통합 검색 인터페이스로 쓰인다.
invoke를 호출하면 내부적으로 similarity_search를 실행하지만 몇 가지 기능을 더 제공한다.
- search_type (예: similarity, mmr, similarity_score_threshold) 변경 가능
- search_kwargs (k, score_threshold, fetch_k 등) 지정 가능
- 캐싱, 커스텀 로직 확장에 더 유연함
- 반환값은 역시 List[Document], 하지만 LangChain 체인과 호환되는 방식으로 제공
즉, PoC나 테스트 용도로는 similarity_search를 바로 써도 되지만,
실제 RAG 시스템이나 LLM QA 파이프라인에 연결할 때는 반드시 retriever를 쓰는 게 권장된다.
as_retriever 메서드는 VectorStore 객체를 기반으로 VectorStoreRetriever를 초기화하고 반환한다.
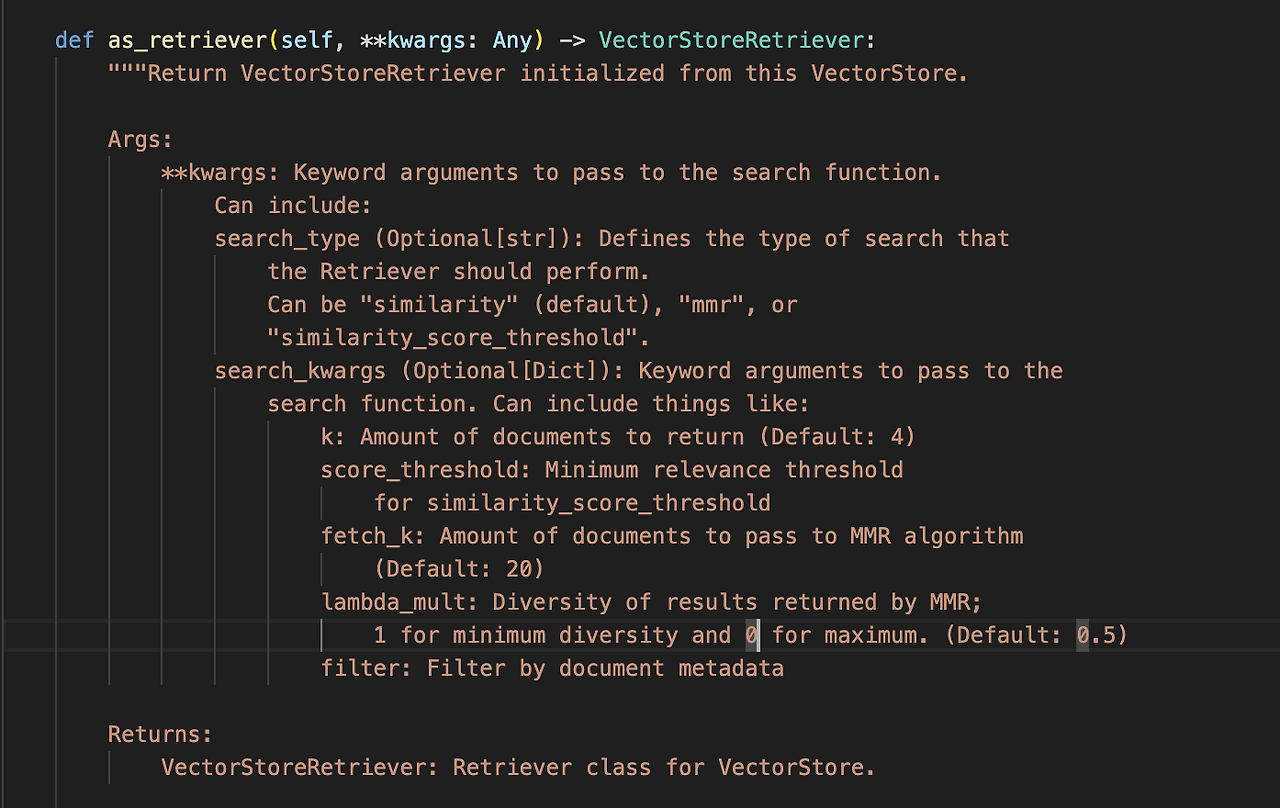
- **kwargs: 검색 함수에 전달할 키워드 인자
- search_type: 검색 유형 ("similarity", "mmr", "similarity_score_threshold")
- search_kwargs: 추가 검색 옵션
- k: 반환할 문서 수 (기본값: 4)
- score_threshold: similarity_score_threshold 검색의 최소 유사도 임계값
- fetch_k: MMR 알고리즘에 전달할 문서 수 (기본값: 20)
- lambda_mult: MMR 결과의 다양성 조절 (0-1 사이, 기본값: 0.5)
- filter: 문서 메타데이터 기반 필터링
- 다양한 검색 전략 구현 가능 (유사도, MMR, 임계값 기반)
- MMR (Maximal Marginal Relevance) 알고리즘으로 검색 결과의 다양성 조절 가능
- MMR 방식은 쿼리에 대한 관련 항목을 검색할 때 검색된 문서의 중복 을 피하는 방법 중 하나
- 메타데이터 필터링으로 특정 조건의 문서만 검색 가능
- tags 매개변수를 통해 검색기에 태그 추가 가능
- search_type과 search_kwargs의 적절한 조합 필요
- MMR 사용 시 fetch_k와 k 값의 균형 조절 필요
- score_threshold 설정 시 너무 높은 값은 검색 결과가 없을 수 있음
- 필터 사용 시 데이터셋의 메타데이터 구조 정확히 파악 필요
- lambda_mult 값이 0에 가까울수록 다양성이 높아지고, 1에 가까울수록 유사성이 높아짐
from langchain_chroma import Chroma
db = Chroma(persist_directory="../news_chroma_db", embedding_function=hf_embeddings)
retriever = db.as_retriever(search_kwargs={"k": 2})
result = retriever.invoke("각국 중앙은행들의 금리 인상 이유는?", )
result728x90
반응형
'Study > AI' 카테고리의 다른 글
| [LangChain] MultiQueryRetriever, 사용자 질문 확장하기 (0) | 2025.08.24 |
|---|---|
| [LangChain] 검색기, Retriever의 search_type, search_kwargs 알아보기 (0) | 2025.08.24 |
| [LangChain] 벡터스토어(VectorStore) ChromaDB, FaissDB 저장하고 불러오기 (1) | 2025.08.21 |
| [LangChain] 벡터스토어(VectorStore)란, Chroma DB (1) | 2025.08.21 |
| [LangChain] HuggingFaceEmbedding (6) | 2025.08.18 |
댓글